

In which I discuss getting the dominant colour from an image quickly...
I have recently made a Discord bot that searches for online versions of board games to help people find games to play remotely. This link will add it to your server.
Discord embeds have a colour bar down the side that can be manually set. I thought it would be cool to have this display the 'average' (i.e. dominant) colour of the board game box and decided to investigate the best way to do it.
For this post I've used these images as examples:

6 Nimmt! board game box which is mostly yellow.

Altiplano board game box art which has a wider variety of colours and it is harder to determine, at a glance, what colour is dominant.
N.B: The Altiplano image has a lower resolution so it is quicker to get the clusters on that image.
TL;DR
The average (mean) of most images is usually brown. That's generally not that useful and when people search for "the average colour of an image" they likely want the average (mode) of an image. We can quickly get the dominant color using k-means clustering. See my code on GitHub that does a comparison of a few methods.
sklearn
The first method I stumbled across was in a Medium post.[1] It leverages sklearn to do this and works pretty well. This is my version based off of that post:
import numpy as np
from sklearn.cluster import KMeans
from skimage import io
def sklearn_dominant_colour(img_url, colours=5):
'''
Dominant Colour method using sklearn, based on:
https://medium.com/analytics-vidhya/colour-separation-in-an-image-using-kmeans-clustering-using-python-f994fa398454
'''
img = io.imread(img_url)
img = img.reshape((-1, 3))
cluster = KMeans(n_clusters=colours)
cluster.fit(img)
labels = cluster.labels_
labels = list(labels)
centroid = cluster.cluster_centers_
percent = []
for i in range(len(centroid)):
j = labels.count(i)
j = j/(len(labels))
percent.append(j)
indices = np.argsort(percent)[::-1]
dominant = centroid[indices[0]]
return dominant, labels, centroidThe version on GitHub also has timing info for each section.
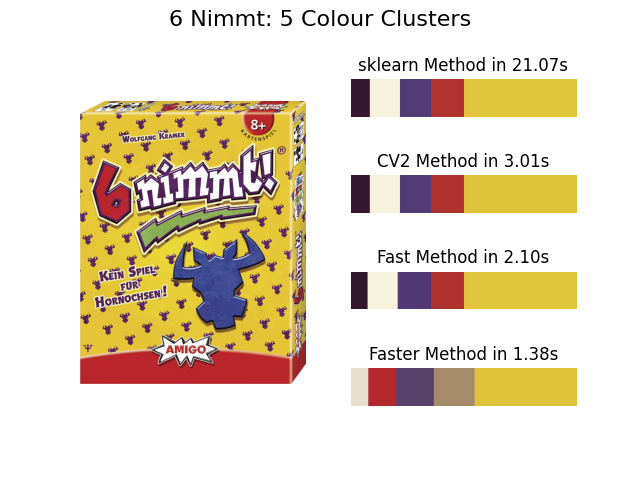
And the results for 5 clusters on our example images:

6 Nimmt, 5 clusters in 21.07s

Altiplano, 5 clusters in 4.24s
The issue with this is that even for 5 clusters it takes 21 seconds to run on the 6 Nimmt! image. For a nice to have, frivolous, feature of my bot I can't increase the time taken for an embed to be returned by that much. So I needed to look for other methods.
OpenCV
The second method I found was in a Stack Overflow answer.[2] This method definitely works and has a really nice example with a set of LEGO bricks in the answer.
My version of this is as so:
import numpy as np
from cv2 import cv2
from skimage import io
def cv2_dominant_colour(img_url, colours=5):
'''
Dominant Colour method using open cv, based on
https://stackoverflow.com/a/43111221/2523885
'''
img = io.imread(img_url)
pixels = np.float32(img.reshape(-1, 3))
n_colours = colours
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 200, .1)
flags = cv2.KMEANS_RANDOM_CENTERS
_, labels, centroid = cv2.kmeans(pixels, n_colours, None, criteria, 10, flags)
labels = labels.flatten().tolist()
_, counts = np.unique(labels, return_counts=True)
dominant = centroid[np.argmax(counts)]
return dominant, labels, centroidThe version on GitHub also has timing info for each section.
And the results for 5 clusters on our example images:

6 Nimmt, 5 clusters in 3.01s

Altiplano, 5 clusters in 0.78s
Faster, yes! But still a few seconds per image is probably too long for my bot that I want to be fairly responsive.
Speeding it Up
I really wanted to get this down to, at most, a second per image. That seemed like a reasonable goal if I could improve the efficiency of the algorithm.
Fast Method
So this was my first attempt at speeding up the algorithm by playing around with tolerances. Turns out the CV2 method was pretty well optimised so actually I ended up speeding up the sklearn version:
import numpy as np
from sklearn.cluster import KMeans
from skimage import io
def fast_dominant_colour(img_url, colours=5):
'''
Faster method for web use that speeds up the sklearn variant.
'''
img = io.imread(img_url)
img = img.reshape((-1, 3))
cluster = KMeans(n_clusters=colours, n_init=3, max_iter=10, tol=0.001)
cluster.fit(img)
labels = cluster.labels_
centroid = cluster.cluster_centers_
percent = []
_, counts = np.unique(labels, return_counts=True)
for i in range(len(centroid)):
j = counts[i]
j = j/(len(labels))
percent.append(j)
indices = np.argsort(percent)[::-1]
dominant = centroid[indices[0]]
return dominant, labels, centroidThis allows us to improve it further still:

6 Nimmt, 5 clusters in 2.10s

Altiplano, 5 clusters in 0.78s
Altiplano is matching CV2 now but this method is otherwise faster (also faster with more clusters, see the gallery below).
Faster Method
Now we can go a step further and reduce the number of pixels we have to process by resampling the image before we get our clusters. Scaling the image to 1/10th the size we get:
import numpy as np
from sklearn.cluster import KMeans
from skimage import io
from skimage.transform import rescale
def fast_dominant_colour(img_url, colours=5, scale=0.1):
'''
Faster method for web use that speeds up the sklearn variant.
Also can use a scaling factor to improve the speed at cost of
accuracy
'''
img = io.imread(img_url)
if scale != 1.0:
img = rescale(img, scale, multichannel=True)
img = img * 255
img = img.reshape((-1, 3))
cluster = KMeans(n_clusters=colours, n_init=3, max_iter=10, tol=0.001)
cluster.fit(img)
labels = cluster.labels_
centroid = cluster.cluster_centers_
percent = []
_, counts = np.unique(labels, return_counts=True)
for i in range(len(centroid)):
j = counts[i]
j = j/(len(labels))
percent.append(j)
indices = np.argsort(percent)[::-1]
dominant = centroid[indices[0]]
return dominant, labels, centroidNow this certainly introduces more errors. You can see that in the examples below. For a larger image with one main colour like 6 Nimmt we still get the correct dominant colour but in Altiplano it does not match the other methods.
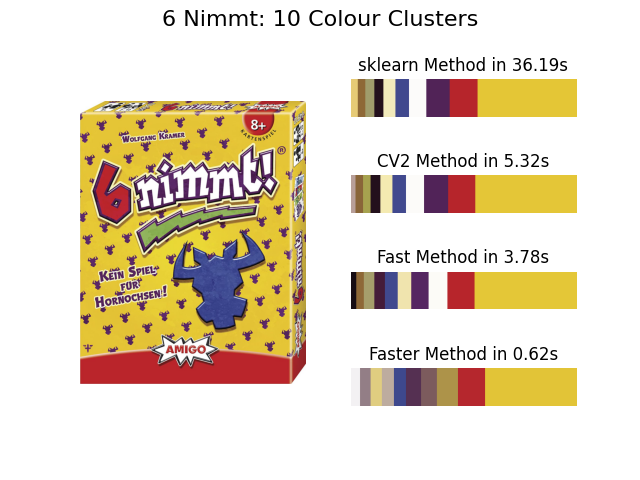
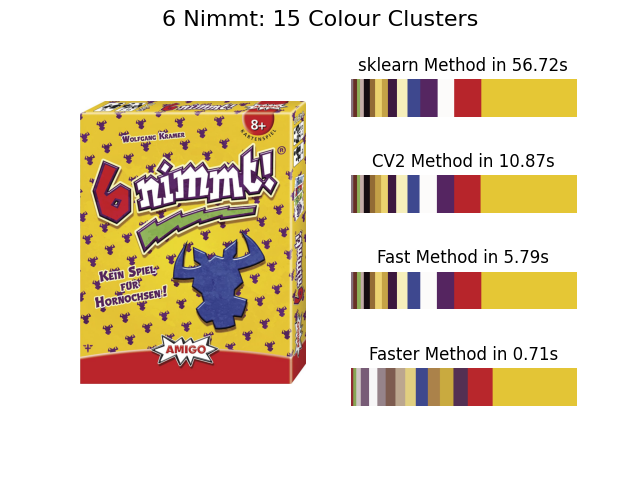



The fast method is therefore probably the best option but scaling can still be useful...
Running On a Web Server
I have a fairly simple Linux webserver I use to host my bots and a website. This falls over due to a very large numpy array if you have a high def image so I added a very simple check into my bot code to use the fastest method if the image is larger than 1080p:
if shape[0] > 1920 and shape[1] > 1080:
img = rescale(img, 0.1, multichannel=True)
img = img * 255
if debug:
print(f'x0.10 Scaled shape: {np.shape(img)}')And now my bot can add a snazzy coloured embed, here are some examples:
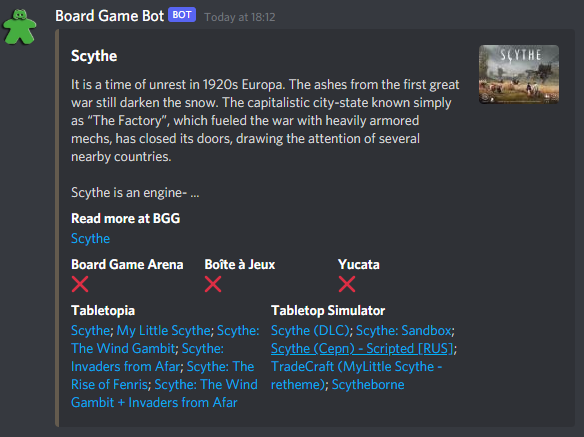
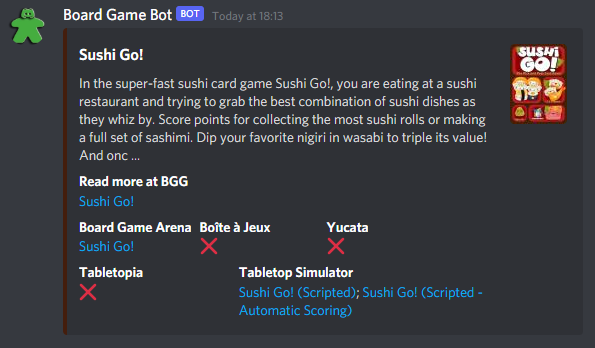
So I hope you find that helpful if you want to (relatively quickly) extract the dominant colour from an image. The git repo showing the comparisons above is a place to start if you want to use these functions.
Tom Out!
References
1. Color Separation in an Image using KMeans Clustering using Python
2. How to find the average colour of an image in Python with OpenCV?